LLMs trained on web-scale corpora inadvertently memorize and leak personally identifiable information (PII) present in their training data. We investigate inference-time interventions to suppress this privacy leakage. We evaluate three editing strategies: activation patching with computed steering vectors (APNEAP), random Gaussian noise steering, and Spectral Editing of Activations (SEA). Using the Enron email corpus with GPT-Neo-1.3B and finetuned Qwen3-8B-enron, we measure targeted PII suppression via exposure metrics like mean reciprocal rank (MRR), and utility via perplexity.
This blog is abbreviated from work done jointly with two classmates, Coby Kassner and Yejun Yun, as a part of Yale's Trustworthy Deep Learning class taught by Rex Ying. Our implementation is available here.
tl;dr
- APNEAP: Achieves 43.2% MRR suppression and 30.6% exposure reduction with 5.2% perplexity degradation on
GPT-Neo-1.3Bwith 759 privacy neurons - Random noise steering: Performs comparably, achieving 42.9% MRR suppression and 43.6% exposure reduction (superior to APNEAP) with 7.9% perplexity degradation, suggesting that identifying privacy neurons is more critical than the specific steering direction
- SEA: Achieves the strongest privacy protection (65.6% MRR suppression, 67.4% exposure reduction) but at substantial utility cost (37.5% perplexity increase) and shows limited effectiveness on finetuned models (0.6% exposure, 6.4% MRR reduction on
Qwen3-8B-enron) - Key insight: Simpler undirected interventions (random noise) can be as effective as complex steering-based approaches, with privacy neuron identification being the critical component
introduction
LLMs trained on web-scale datasets memorize verbatim snippets from their training data, including personally identifiable information (PII) such as email addresses and phone numbers. Adversarial prompts can extract this memorized data with alarming success rates, and larger models memorize more (largely due to data duplication). Traditional mitigation strategies—data preprocessing, differential privacy, and machine unlearning—each have limitations: preprocessing misses patterns, differential privacy degrades quality, and unlearning requires expensive retraining.
Recent work has shown that privacy leakage is mechanistically localized: specific neurons in transformer feedforward layers are disproportionately responsible for memorizing and recalling private information. This enables targeted editing: by identifying "privacy neurons" through gradient attribution and selectively intervening on their activations at inference time, we can reduce leakage while preserving general model capabilities.
what's different
Our implementation extends prior work in several ways. First, we adapt SEA, originally designed for truthfulness and bias, to the privacy domain by formulating PII suppression as a subspace projection problem. Second, we provide a modular, reusable codebase that separates attribution, selection, and editing into independent stages, enabling future researchers to swap out components easily. Third, we introduce the option to use layer-suffix editing and to scope spectral projections to privacy neurons only, hybridizing the targeted nature of APNEAP with the principled subspace geometry of SEA.
problem definition
We consider the following setting: a pretrained language model $M_\theta$ has been trained on a large corpus $\mathcal{D}$ that contains personally identifiable information. Given a prompt $X$ that provides context mentioning or related to a private entity, the model may generate a continuation $Y$ that leaks the associated private information (e.g., an email address, phone number, or social security number). Formally, we define a privacy leak as a tuple $(X, Y)$ where:
for some threshold $\tau$, indicating that the model assigns high probability to generating the private sequence $Y$ given the prompt $X$.
Our goal is to develop an inference-time intervention $\mathcal{E}$ that modifies the model's internal activations such that the edited model $M_{\mathcal{E}}$ satisfies:
where $\mathcal{T}$ is a set of known privacy leaks (the targeted PII we want to suppress), $\mathcal{V}$ is a validation corpus of non-sensitive text, and PPL denotes perplexity (our measure of general model utility). This formulation seeks to reduce the probability of generating targeted private information while minimizing degradation in language modeling quality.
Base Model: We use GPT-Neo-1.3B, an open-source autoregressive transformer with 24 layers and 3072-dimensional hidden states, trained on the Pile dataset. We also explore Qwen3-8B-enron, finetuned off Qwen3-8B for few epochs on Enron with LoRA.
Trustworthy Aspect: Our project focuses on privacy, specifically mitigating memorization and leakage of personally identifiable information. By developing inference-time interventions that reduce privacy leakage without requiring model retraining, we contribute to making LLMs safer and more aligned with privacy regulations such as GDPR and CCPA.
methods
We evaluate three inference-time editing strategies: (1) APNEAP, which computes steering vectors from sensitive vs. desensitized prompts and additively patches them onto privacy neurons; (2) random Gaussian noise steering, a simpler alternative requiring only privacy neuron coordinates; and (3) SEA, adapted from truthfulness alignment to privacy by projecting activations into subspaces that maximize covariance with desensitized contexts while minimizing covariance with privacy-leaking contexts.
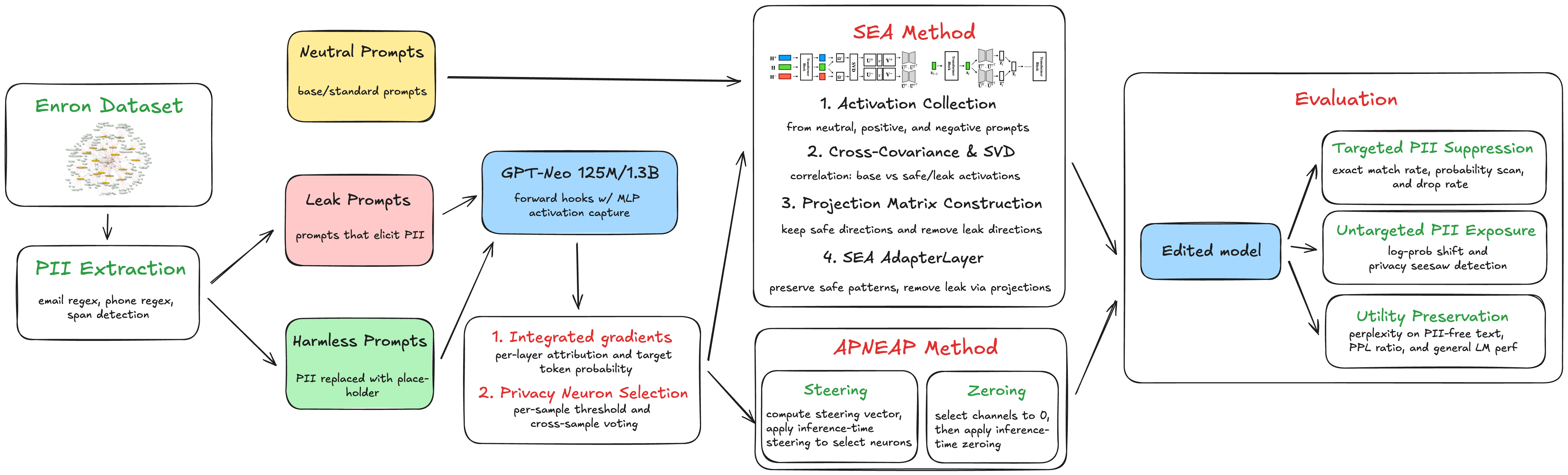
Figure 1: Methodology flowchart showing the full pipeline: privacy neuron attribution via integrated gradients, neuron selection via two-threshold voting, and inference-time activation editing.
privacy neuron attribution
We use integrated gradients to attribute each neuron's contribution to privacy leakage. For a given leak tuple $(X, Y)$, we tokenize $X$ and identify the position $t$ immediately before the first token of the secret $Y$. We then capture the intermediate activation $\mathbf{z}_{\ell}$ at the input to the MLP in layer $\ell$ at position $t$. The integrated gradient for neuron $j$ in layer $\ell$ is approximated as:
where $m=10$ interpolation steps are used, $y_1$ is the first token of the secret $Y$, and the gradient is computed via backpropagation.
privacy neuron selection
Raw attributions are noisy and vary across examples. Following APNEAP, we use a two-threshold voting procedure. For each example $i$ and layer $\ell$:
- Compute $\max_{\ell,i} = \max_j \vert \mathrm{IG}_{\ell,j,i} \vert$
- For text-level threshold, keep neuron $(\ell, j)$ if $\vert \mathrm{IG}{\ell,j,i} \vert > 0.1 \cdot \max{\ell,i}$
We then count how many examples activate each neuron and retain neurons that appear in more than 50% of examples (batch-level threshold). The result is a set $\mathcal{N} = {(\ell, j)}$ of privacy neuron coordinates.
activation patching
For each leak example $(X, Y)$, we construct a harmless variant $X'$ by replacing the secret $Y$ with a placeholder token. We compute the steering vector as the mean difference:
At inference time, we register PyTorch forward hooks that modify the MLP activations:
where $\alpha=10$ is a scaling hyperparameter and $\mathbf{m}_{\ell}$ is a binary mask that is 1 for privacy neurons in $\mathcal{N}$ and 0 otherwise.
As a simpler alternative, we also evaluate steering with random Gaussian noise by replacing the computed steering vector with freshly sampled noise $\epsilon_{\ell} \sim \mathcal{N}(0, \sigma^2 \mathbf{I})$ on each forward pass.
spectral editing of activations
We adapt SEA to privacy by constructing three variants for each leak $(X, Y)$:
- Neutral: Remove the secret $Y$ and its surrounding context
- Positive (harmless): Replace $Y$ with a placeholder
- Negative (leak): Keep the original prompt $X$ that leaks $Y$
We perform forward passes on all three variants, capturing the last-token MLP activations for each layer $\ell$. Stacking these across all examples yields matrices $\mathbf{H}_{\ell}^{(0), (+), (-)}$ of shape $N \times d$. We center each matrix and compute cross-covariance matrices, perform SVD, and retain the top $k^+$ (positive) and bottom $k^-$ (negative) singular vectors. The projection matrices are:
At inference, we apply both projections and renormalize:
results
dataset
We use the CMU Enron email dataset (~500,000 emails from 150 employees). We extract email bodies and scan for PII (email addresses and phone numbers) using regular expressions. For each detected PII span, we extract a contextual prefix (up to 128 tokens) as the prompt $X$ and the PII as the secret $Y$. We score candidates using an exposure metric against a candidate set of 100,000 entries. This yields a curated evaluation set of ~200 samples.
evaluation metrics
- Exposure: $\mathrm{Exposure}(X, Y) = \log_2(|R|^n) - \log_2(r)$ where $|R|$ is the size of the candidate token set. Higher exposure indicates stronger privacy leakage.
- Mean Reciprocal Rank (MRR): $\mathrm{MRR}(X, Y) = \frac{1}{n} \sum_{i=1}^{n} \frac{1}{r_i}$. Lower MRR after editing indicates better privacy protection.
- Perplexity (PPL): $\mathrm{PPL} = \exp\left( -\frac{1}{|\mathcal{V}|} \sum_{i=1}^{|\mathcal{V}|} \log P(x_i \mid x_{<i}) \right)$. Lower perplexity indicates better utility.
main results
| Method | MRR | Exposure | PPL |
|---|---|---|---|
| Base | 0.26 | 114.30 | 9.61 |
| APNEAP | −43.2% | −30.6% | 10.11 |
| Random Noise | −42.9% | −43.6% | 10.37 |
| SEA | −65.6% | −67.4% | 13.21 |
APNEAP achieves 43.2% MRR suppression and 30.6% exposure reduction with 5.2% perplexity degradation. Random noise steering performs comparably (42.9% MRR, 43.6% exposure reduction) with 7.9% perplexity degradation—suggesting that identifying privacy neurons is more critical than the specific steering direction. SEA achieves the strongest privacy protection (65.6% MRR, 67.4% exposure reduction) but at substantial utility cost (37.5% perplexity increase). On Qwen3-8B-enron, SEA shows limited effectiveness (0.6% exposure, 6.4% MRR reduction), likely because finetuning embeds secrets more deeply in the model's representations.
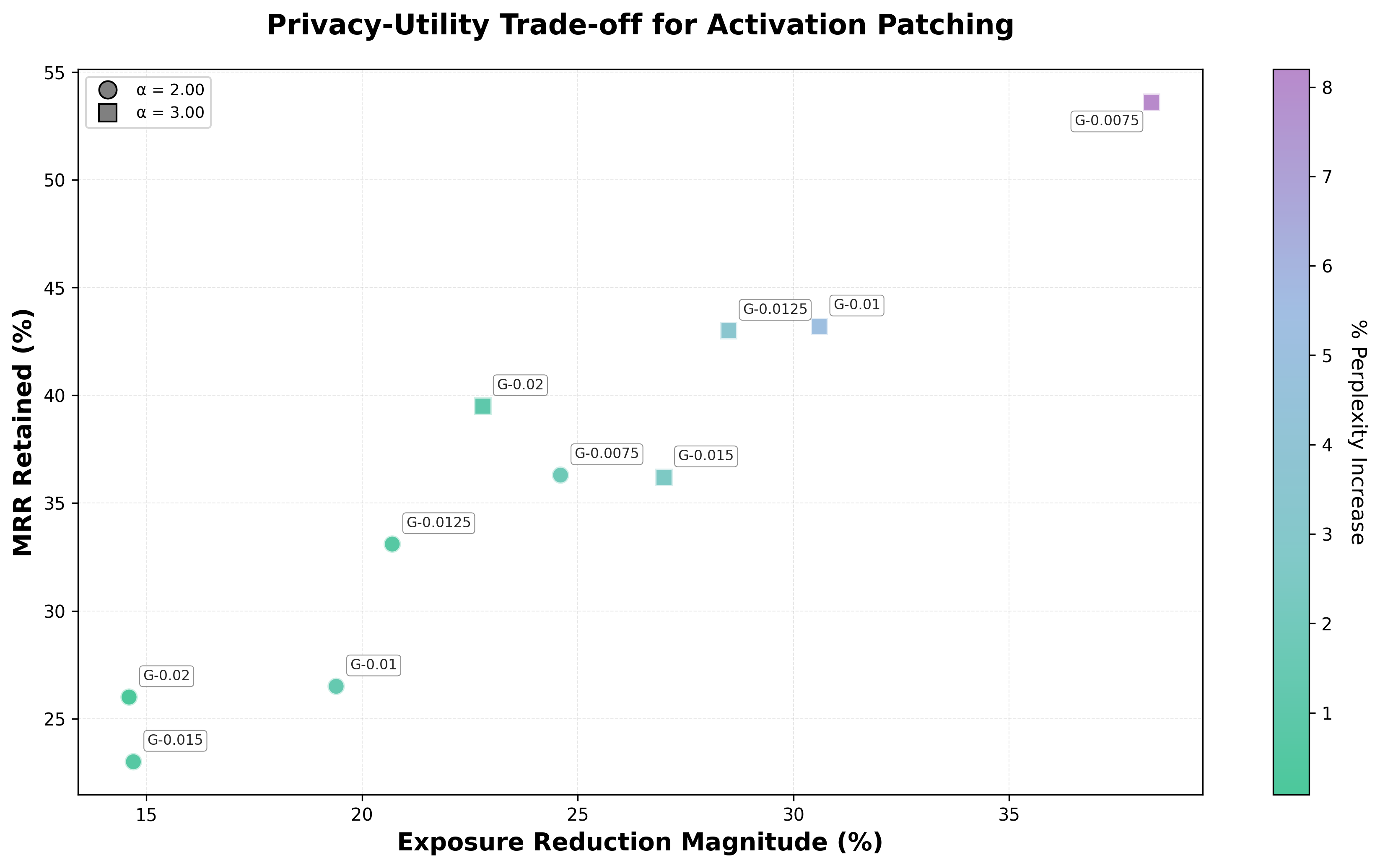
Figure 2: Activation patching results across privacy neuron thresholds and alphas. Marker shapes indicate α values (circle = 2.00, square = 3.00). Color indicates % perplexity increase. Negative percentages indicate privacy improvement.
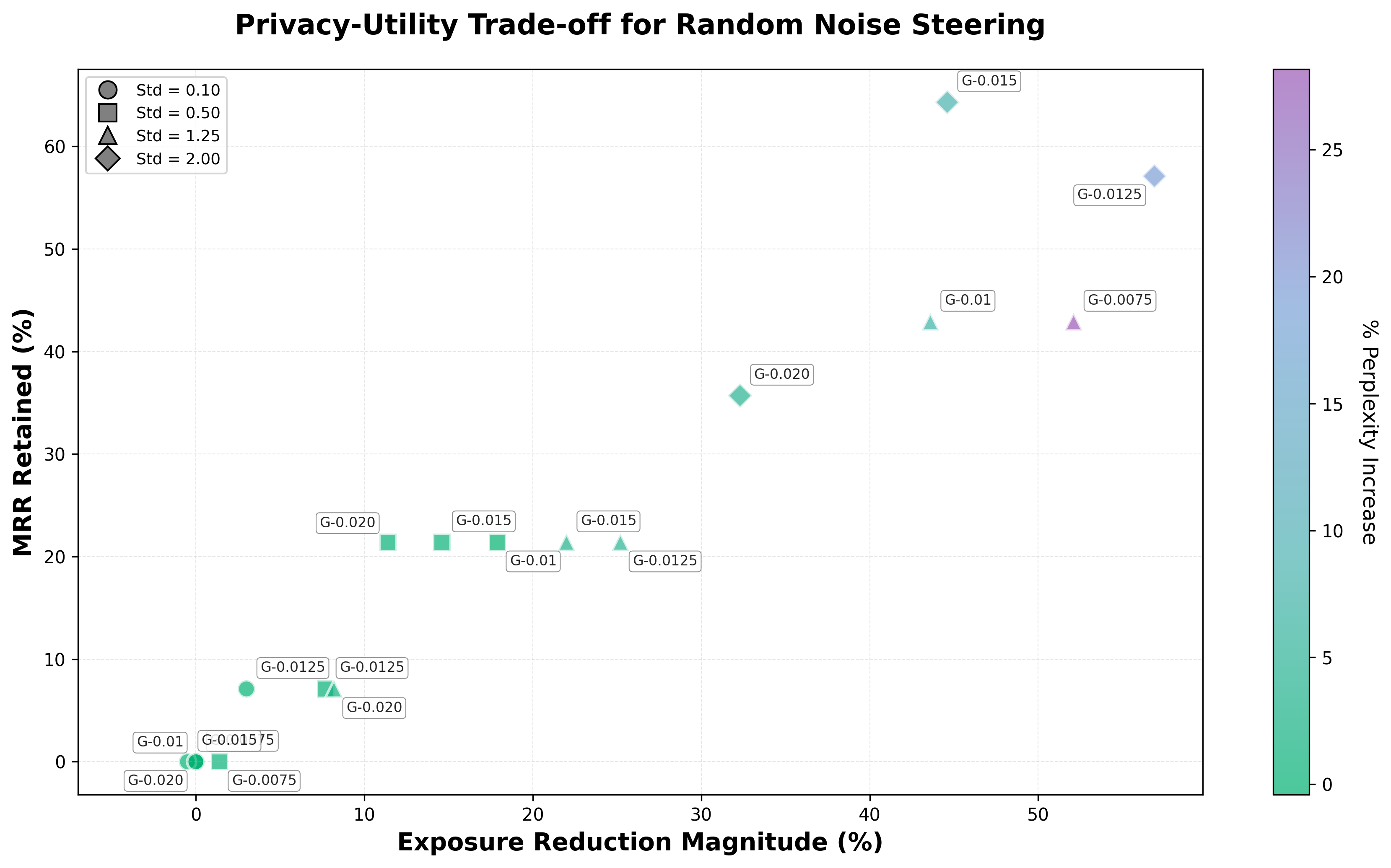
Figure 3: Random noise steering results across privacy neuron thresholds and noise levels. Marker shapes indicate standard deviation values (circle = 0.10, square = 0.50, triangle = 1.25, diamond = 2.00). Color indicates % perplexity increase. Negative percentages indicate privacy improvement.
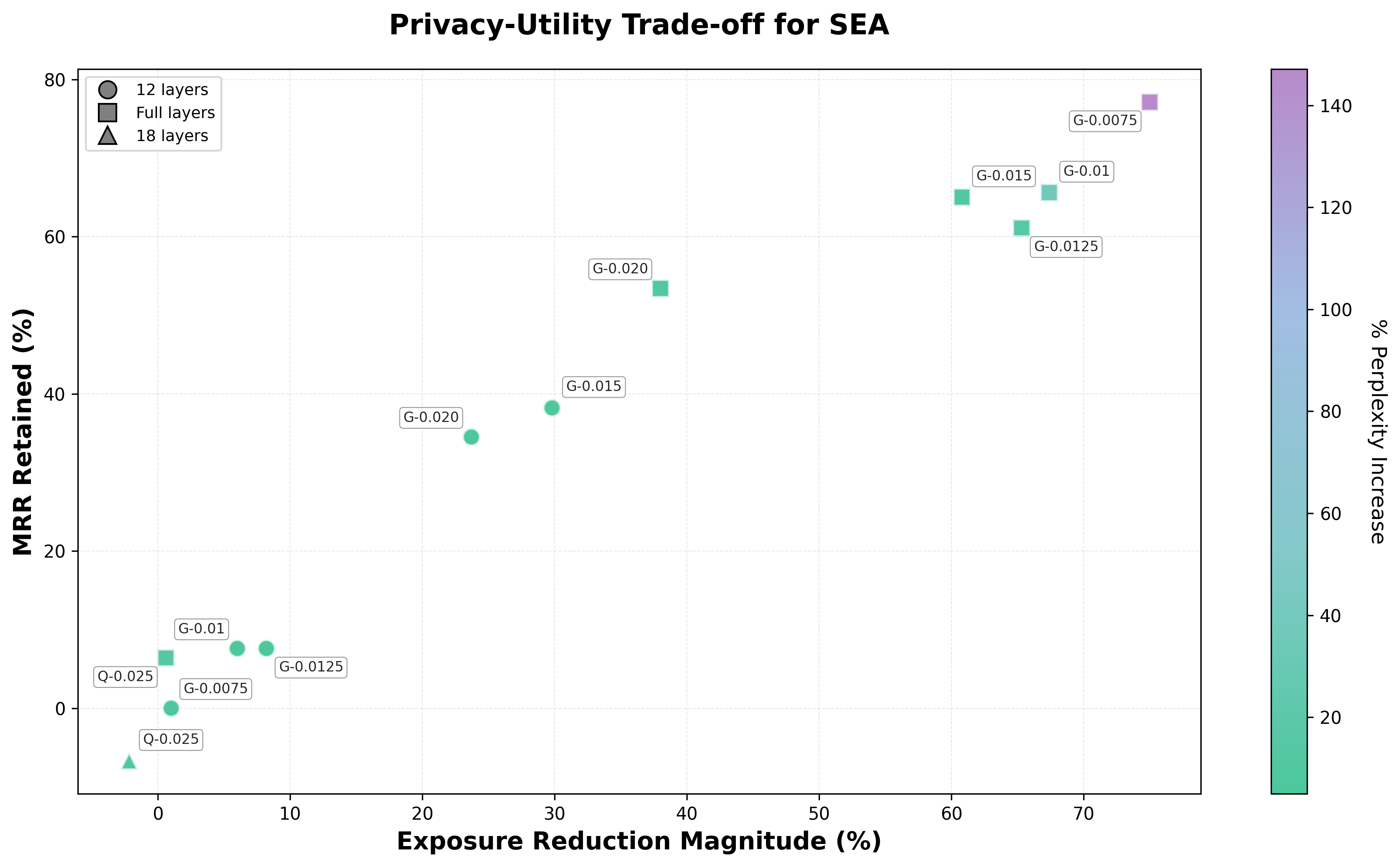
Figure 4: SEA results for GPT-Neo-1.3B and Qwen3-8B-enron models. Marker shapes indicate layers edited (circle = 12 layers, square = full layers, triangle = 18 layers). Color indicates % perplexity increase.
ablation study
We conduct ablations across privacy neuron count, editing strength, and steering method. By varying the selection threshold $\tau_{\mathrm{text}}$ from 0.0075 to 0.20 we obtain neuron sets ranging from 2,303 down to 34 neurons. Larger sets achieve stronger privacy suppression but at greater utility cost. Both activation patching and random noise show a consistent trade-off: stronger interventions yield greater exposure reduction at the cost of increased perplexity.
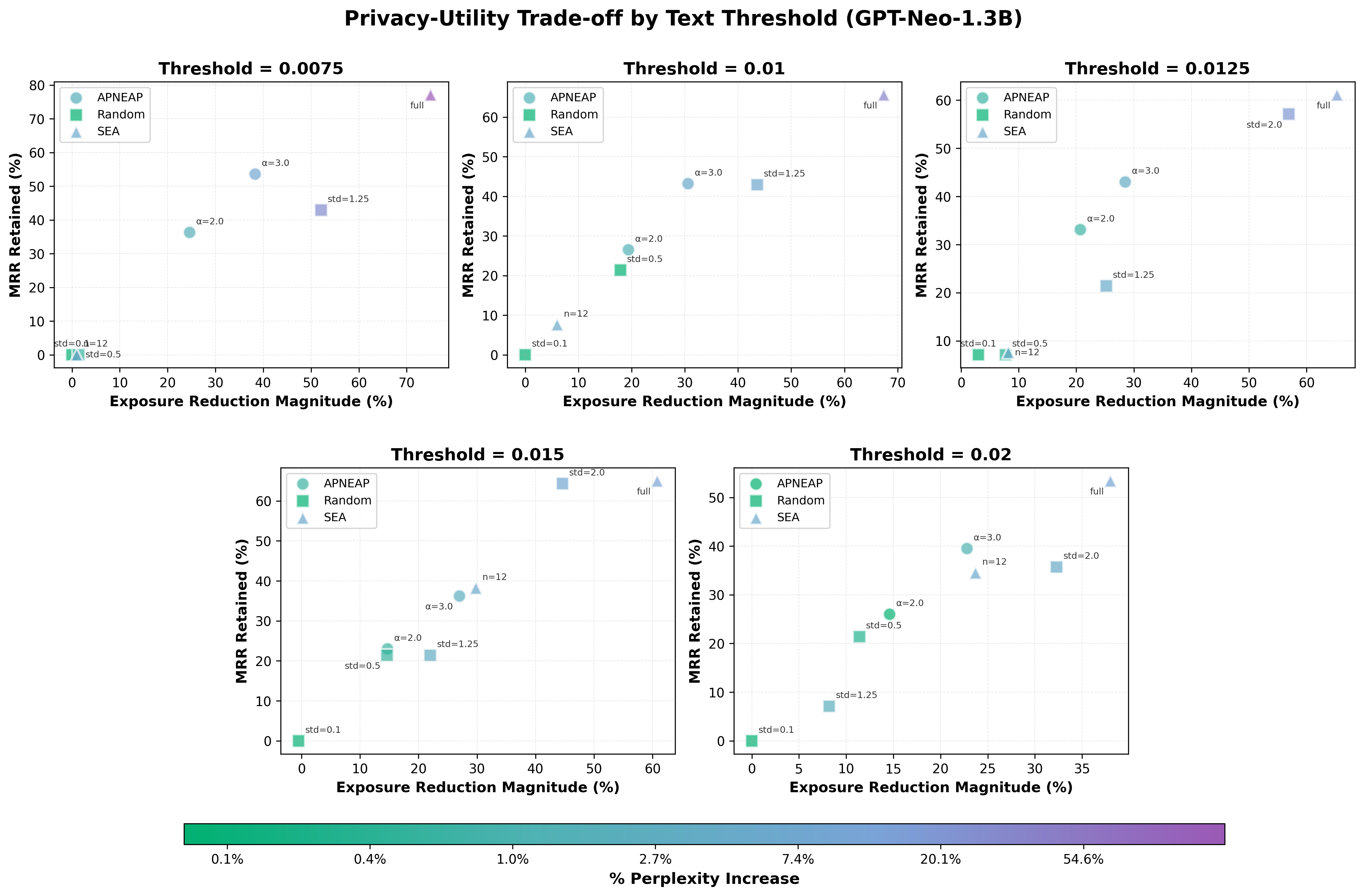
Figure 5: Comparison of APNEAP, Random Noise Steering, and SEA across different text thresholds. Each subplot shows results for a specific threshold; marker shapes indicate method type (circle = APNEAP, square = Random, triangle = SEA). Color indicates % perplexity increase on a log scale. All methods show a consistent privacy-utility trade-off across thresholds.
conclusion
We implement and evaluate three inference-time privacy editing strategies. Identifying privacy neurons is more critical than the specific steering direction—random noise steering performs comparably to directed APNEAP. SEA achieves the strongest protection but at substantial utility cost and shows limited effectiveness on finetuned models. Inference-time editing is a viable strategy when retraining is infeasible; it should be combined with preprocessing, differential privacy, and careful data curation for high-stakes privacy protection.
next steps
- Evaluate additional text thresholds on finetuned models
- Test robustness to adversarial prompts that try to bypass privacy protections
- Try other model architectures to see if privacy neuron localization works broadly
- Combine inference-time editing with training-time techniques like differential privacy or data filtering
- Scale to larger models (7B+ parameters) to see if the privacy-utility trade-offs hold